Splitgraph has been acquired by EDB! Read the blog post.
Throwing away the backend: Towards a data delivery network
We discuss the trends of serverless and edge computing, talk about why our SQL server is open to the public and propose the idea of a data delivery network.
Serverless and edge computing have allowed application developers to bring their applications closer to the end user.
Instead of maintaining a group of servers in a single location, developers can let companies like Cloudflare, Fastly or Akamai handle their content delivery.
With Function as a service, companies pay for what they use. They can avoid having to provision a server that stays idle most of the time.
In this article, we want to talk about these trends and how we can apply them to databases. We'll also talk about our decision to make the API for our Splitgraph registry work over a public SQL connection. We'll use this experience to propose the idea of a data delivery network.
How content delivery networks work
Content delivery networks provide a straightforward way to scale a read-only HTTP layer. They use existing HTTP cache semantics like the Cache-Control header. The developer only needs to point their DNS records to use the CDN's nameservers. The CDN handles everything else for them. It has points of presence around the world and peering agreements with other ISPs. It can selectively cache data, handle DDoS protection and offer extra services on top.
The value proposition behind edge computing is simple. For a lot of companies, scaling compute is not their core competency. They can spend time and money provisioning servers and configuring something like Varnish. Or, they can use services that will handle scaling and caching for them.
However, applications still need to run SQL queries. A CDN doesn't completely help an application that performs client-side rendering. The database becomes the next performance bottleneck in scaling a service.
There are many ways to scale a database, for example, replication or sharding. But again, this requires specialist knowledge about a database that is easy to get wrong.
Why do you need a backend, anyway?
Let's change gears and consider a classic Web application. It consists of the frontend, the backend and the database.
There are several purposes that a backend serves:
- Business logic. The backend converts higher level API calls into low-level SQL queries. It prepares data for presentation and writes it back when needed.
- Authorization. The backend acts as a security barrier, validating API calls. This is necessary because the frontend is running on the user's machine: the client is not trusted.
- Multiplexing. A database connection has a larger overhead than an HTTP connection. A backend can shunt hundreds of simultaneous clients over to a few database connections.
Alternatives to CRUD services
One big issue with writing RESTful backends is that there's a lot of boilerplate. The programmer has to write very similar code to handle every action. They have to care of validation, typechecking and handling edge cases.
Libraries like PostgREST and PostGraphile have helped developers decrease iteration times. They introspect database schemas and generate REST and GraphQL APIs for them.
PostgREST and PostGraphile perform their authorization using database methods like row level security. In essence, they decrease the size of the "trusted computing base".
Often, services that use these kinds of tools don't even have a separate backend. Client side code can call the automatically generated GraphQL/REST API directly.
Splitgraph's architecture
The database can perform a lot of work that the backend does more quickly and more efficiently.
We use this idea in the API for the Splitgraph registry that allows you to push and pull data images. A Splitgraph client can access it over a normal PostgreSQL connection to postgresql://data.splitgraph.com:5432/sgregistry.
Our API implements all business logic as PostgreSQL functions. This has a few immediate advantages:
- Lets PostgreSQL precompile them
- Avoids an extra hop from the backend, decreasing latency
- Makes basic validation and type checking trivial. It's not possible to call a function with a wrong number of arguments or different types.
For more complex logic, we wrote it in higher-level languages like PL/Python or PL/Lua. PostgreSQL even supports languages like C or JavaScript.
We solved the problem of multiplexing and authorization by adding PgBouncer, a connection pooler, in front of our database. Our fork of PgBouncer injects a signed cookie into every transaction as a local variable. Downstream procedures validate this cookie for authentication and authorization. This lets us decouple PostgreSQL users from application users. Multiple inbound sessions can use the same connection.
Our fork of PgBouncer even inspects queries on the fly and filters them. This makes sure that the client can only call Splitgraph SQL API functions.
For the web frontend at www.splitgraph.com, we use PostGraphile. Besides not having to write an extra API server, it lets us generate TypeScript client code.
Data delivery network
We can apply these ideas and concepts to the problem of building a "data delivery network". Such a network would completely abstract away all the issues around making sure that data is available at the edge. It can also provide plenty of other useful services.
Here's a quick sketch of what a DDN's administration interface would look like:
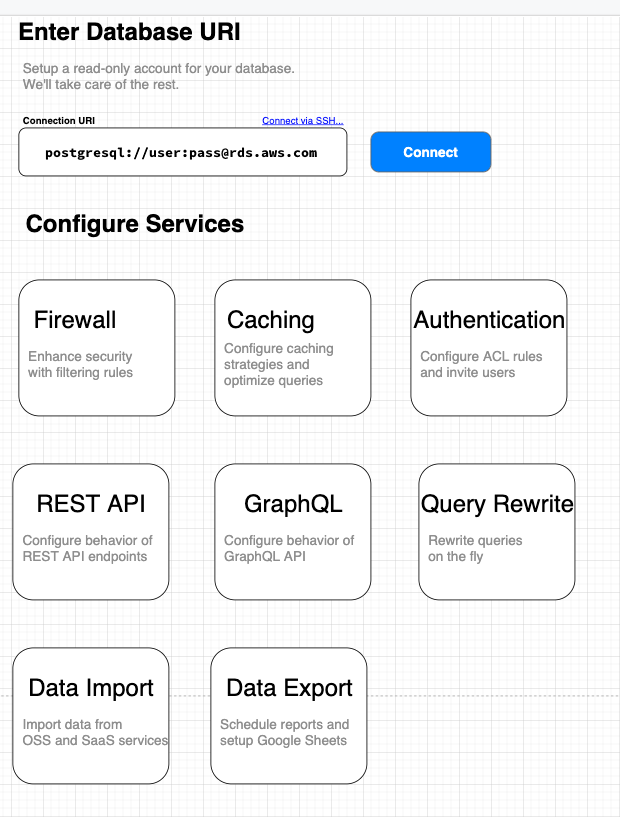
To use a DDN, a developer would create a read-only account on their database and give the DDN the credentials. It will then make a few services available:
The DDN will create an SQL endpoint. Any existing SQL client or application will be able to connect to it and run queries.
Besides SQL, the DDN will also be able to introspect the origin database and provide REST and GraphQL API endpoints. A client, running in the user's web browser, can use these endpoints instead of a backend server.
The DDN will be able to cache read-only SQL transactions with configurable policies. It will only forward the query to the origin database if there's a cache miss or expiry.
The client code doesn't need to be trusted. The DDN can intercept and firewall queries or rate limit them. To simplify migrations, the DDN can rewrite queries on the fly before forwarding them.
The DDN's work doesn't need to stop at handling queries. It can also manage data imports and exports. For example, it can make data from other services available to clients. Or, it can export data to Google Sheets or a data warehouse.
In the case of Splitgraph, we envision you being able to even run a JOIN across a public Splitgraph image and your private data.
Conclusion
The database is the next frontier of serverless and edge computing. One of Splitgraph's goals is building a data delivery network to handle these problems.
If you're interested in learning more about Splitgraph, you can check our frequently asked questions section, follow our quick start guide or visit our website.
Splitgraph
Made with


on four continents.